Multi-objective optimization with Expected HyperVolume Improvement#
[1]:
import math
import gpflow
import matplotlib.pyplot as plt
import numpy as np
import tensorflow as tf
from trieste.experimental.plotting import (
plot_bo_points,
plot_function_2d,
plot_mobo_history,
plot_mobo_points_in_obj_space,
)
[2]:
import trieste
from trieste.acquisition.function import ExpectedHypervolumeImprovement
from trieste.acquisition.rule import EfficientGlobalOptimization
from trieste.data import Dataset
from trieste.models import TrainableModelStack
from trieste.models.gpflow import build_gpr, GaussianProcessRegression
from trieste.space import Box, SearchSpace
from trieste.objectives.multi_objectives import VLMOP2
from trieste.acquisition.multi_objective.pareto import (
Pareto,
get_reference_point,
)
np.random.seed(1793)
tf.random.set_seed(1793)
Describe the problem#
In this tutorial, we provide a multi-objective optimization example using the expected hypervolume improvement acquisition function. We consider the VLMOP2 problem — a synthetic benchmark problem with two objectives and input dimensionality of two. We start by defining the problem parameters.
[3]:
vlmop2 = VLMOP2(2)
observer = trieste.objectives.utils.mk_observer(vlmop2.objective)
[4]:
mins = [-2, -2]
maxs = [2, 2]
search_space = Box(mins, maxs)
num_objective = 2
Let’s randomly sample some initial data from the observer …
[5]:
num_initial_points = 20
initial_query_points = search_space.sample(num_initial_points)
initial_data = observer(initial_query_points)
… and visualise the data across the design space: each figure contains the contour lines of each objective function.
[6]:
_, ax = plot_function_2d(
vlmop2.objective,
mins,
maxs,
contour=True,
title=["Obj 1", "Obj 2"],
figsize=(12, 6),
colorbar=True,
xlabel="$X_1$",
ylabel="$X_2$",
)
plot_bo_points(initial_query_points, ax=ax[0, 0], num_init=num_initial_points)
plot_bo_points(initial_query_points, ax=ax[0, 1], num_init=num_initial_points)
plt.show()
/opt/hostedtoolcache/Python/3.10.12/x64/lib/python3.10/site-packages/matplotlib/_mathtext.py:1880: UserWarning: warn_name_set_on_empty_Forward: setting results name 'sym' on Forward expression that has no contained expression
- p.placeable("sym"))
/opt/hostedtoolcache/Python/3.10.12/x64/lib/python3.10/site-packages/matplotlib/_mathtext.py:1885: UserWarning: warn_ungrouped_named_tokens_in_collection: setting results name 'name' on ZeroOrMore expression collides with 'name' on contained expression
"{" + ZeroOrMore(p.simple | p.unknown_symbol)("name") + "}")
… and in the objective space. The plot_mobo_points_in_obj_space will automatically search for non-dominated points and colours them in purple.
[7]:
plot_mobo_points_in_obj_space(initial_data.observations)
plt.show()
Modelling the two functions#
In this example we model the two objective functions individually with their own Gaussian process models, for problems where the objective functions are similar it may make sense to build a joint model.
We use a model wrapper: TrainableModelStack to stack these two independent GPs into a single model working as an (independent) multi-output model. Note that we set the likelihood variance to a small number because we are dealing with a noise-free problem.
[8]:
def build_stacked_independent_objectives_model(
data: Dataset, num_output: int, search_space: SearchSpace
) -> TrainableModelStack:
gprs = []
for idx in range(num_output):
single_obj_data = Dataset(
data.query_points, tf.gather(data.observations, [idx], axis=1)
)
gpr = build_gpr(single_obj_data, search_space, likelihood_variance=1e-7)
gprs.append((GaussianProcessRegression(gpr), 1))
return TrainableModelStack(*gprs)
[9]:
model = build_stacked_independent_objectives_model(
initial_data, num_objective, search_space
)
Define the acquisition function#
Here we utilize the EHVI: ExpectedHypervolumeImprovement acquisition function:
[10]:
ehvi = ExpectedHypervolumeImprovement()
rule: EfficientGlobalOptimization = EfficientGlobalOptimization(builder=ehvi)
Run the optimization loop#
We can now run the optimization loop
[11]:
num_steps = 30
bo = trieste.bayesian_optimizer.BayesianOptimizer(observer, search_space)
result = bo.optimize(num_steps, initial_data, model, acquisition_rule=rule)
Optimization completed without errors
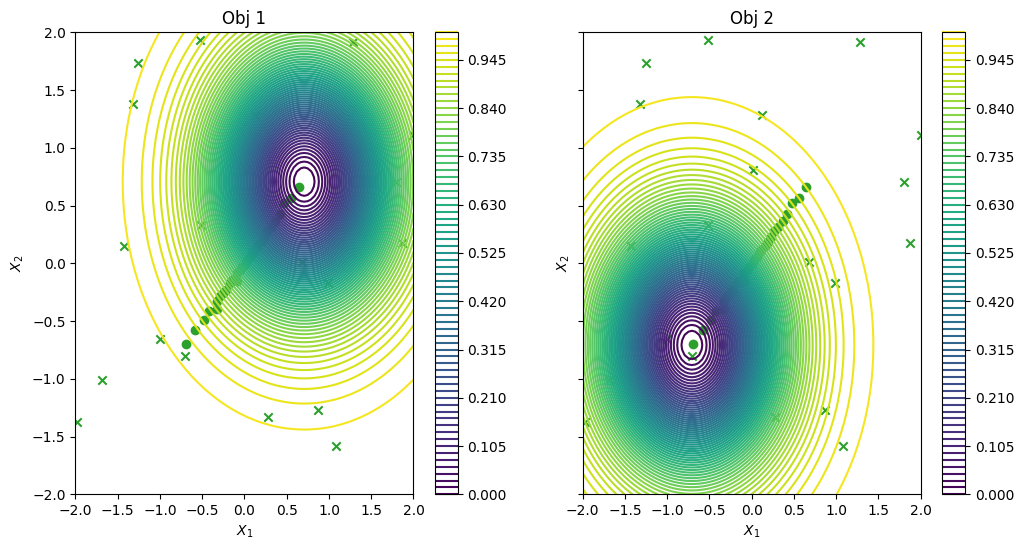
To conclude, we visualize the queried data across the design space. We represent the initial points as crosses and the points obtained by our optimization loop as dots.
[12]:
dataset = result.try_get_final_dataset()
data_query_points = dataset.query_points
data_observations = dataset.observations
_, ax = plot_function_2d(
vlmop2.objective,
mins,
maxs,
contour=True,
figsize=(12, 6),
title=["Obj 1", "Obj 2"],
xlabel="$X_1$",
ylabel="$X_2$",
colorbar=True,
)
plot_bo_points(data_query_points, ax=ax[0, 0], num_init=num_initial_points)
plot_bo_points(data_query_points, ax=ax[0, 1], num_init=num_initial_points)
plt.show()
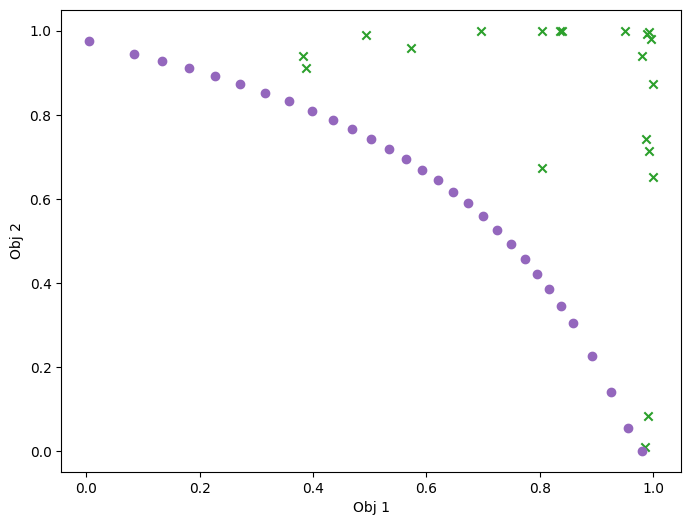
Visualize in objective space. Purple dots denote the non-dominated points.
[13]:
plot_mobo_points_in_obj_space(data_observations, num_init=num_initial_points)
plt.show()
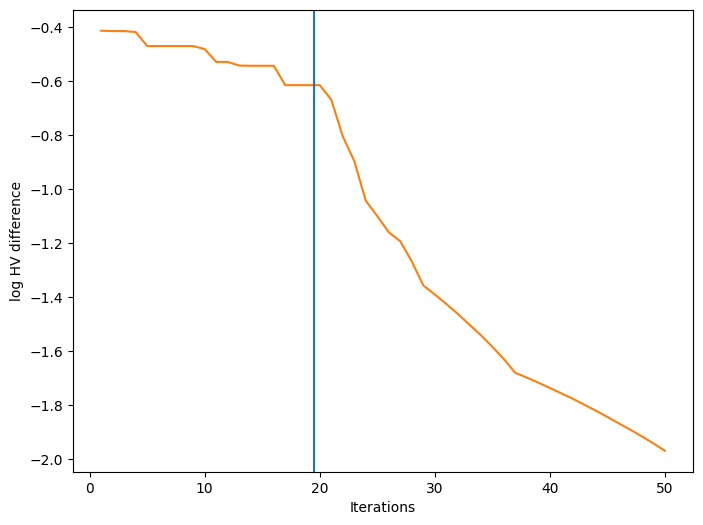
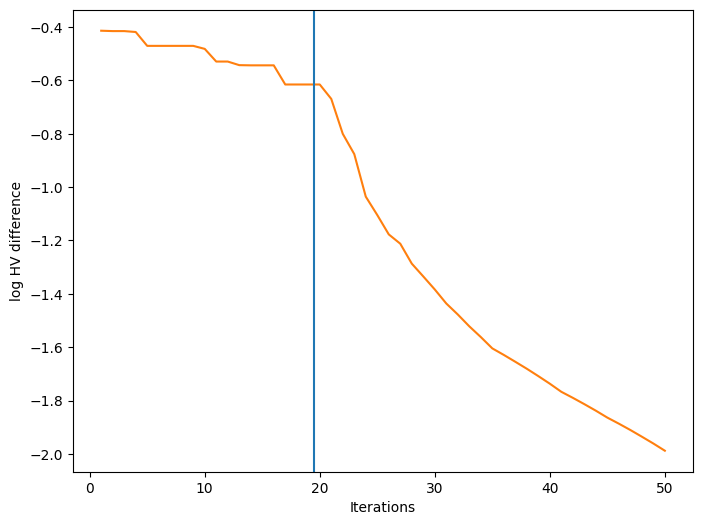
We can also visualize how a performance metric evolved with respect to the number of BO iterations. First, we need to define a performance metric. Many metrics have been considered for multi-objective optimization. Here, we use the log hypervolume difference, defined as the difference between the hypervolume of the actual Pareto front and the hypervolume of the approximate Pareto front based on the bo-obtained data.
First we need to calculate the \(\text{HV}_{\text{actual}}\) based on the actual Pareto front. For some multi-objective synthetic functions like VLMOP2, the actual Pareto front has a clear definition, thus we could use gen_pareto_optimal_points to near uniformly sample on the actual Pareto front. And use these generated Pareto optimal points to (approximately) calculate the hypervolume of the actual Pareto frontier:
[14]:
actual_pf = vlmop2.gen_pareto_optimal_points(100) # gen 100 pf points
ref_point = get_reference_point(data_observations)
idea_hv = Pareto(
tf.cast(actual_pf, dtype=data_observations.dtype)
).hypervolume_indicator(ref_point)
Then we define the metric function:
[15]:
def log_hv(observations):
obs_hv = Pareto(observations).hypervolume_indicator(ref_point)
return math.log10(idea_hv - obs_hv)
Finally, we can plot the convergence of our performance metric over the course of the optimization. The blue vertical line in the figure denotes the time after which BO starts.
[16]:
fig, ax = plot_mobo_history(
data_observations, log_hv, num_init=num_initial_points
)
ax.set_xlabel("Iterations")
ax.set_ylabel("log HV difference")
plt.show()
Batch multi-objective optimization#
EHVI can be extended to the case of batches (i.e. query several points at a time) using the Fantasizer. Fantasizer works by greedily optimising a base acquisition function, then “fantasizing” the observations at the chosen query points and updating the predictive equations of the models as if the fantasized data was added to the models. The only changes that need to be done here are to wrap the ExpectedHypervolumeImprovement in a Fantasizer object, and set the rule argument
num_query_points to a value greater than one. Here, we choose 10 batches of size 3, so the observation budget is the same as before.
[17]:
model = build_stacked_independent_objectives_model(
initial_data, num_objective, search_space
)
from trieste.acquisition.function import Fantasizer
batch_ehvi = Fantasizer(ExpectedHypervolumeImprovement())
batch_rule: EfficientGlobalOptimization = EfficientGlobalOptimization(
builder=batch_ehvi, num_query_points=3
)
num_steps = 10
bo = trieste.bayesian_optimizer.BayesianOptimizer(observer, search_space)
batch_result = bo.optimize(
num_steps, initial_data, model, acquisition_rule=batch_rule
)
WARNING:tensorflow:5 out of the last 283 calls to <function expected_hv_improvement.__call__ at 0x7f5eec373520> triggered tf.function retracing. Tracing is expensive and the excessive number of tracings could be due to (1) creating @tf.function repeatedly in a loop, (2) passing tensors with different shapes, (3) passing Python objects instead of tensors. For (1), please define your @tf.function outside of the loop. For (2), @tf.function has reduce_retracing=True option that can avoid unnecessary retracing. For (3), please refer to https://www.tensorflow.org/guide/function#controlling_retracing and https://www.tensorflow.org/api_docs/python/tf/function for more details.
Optimization completed without errors
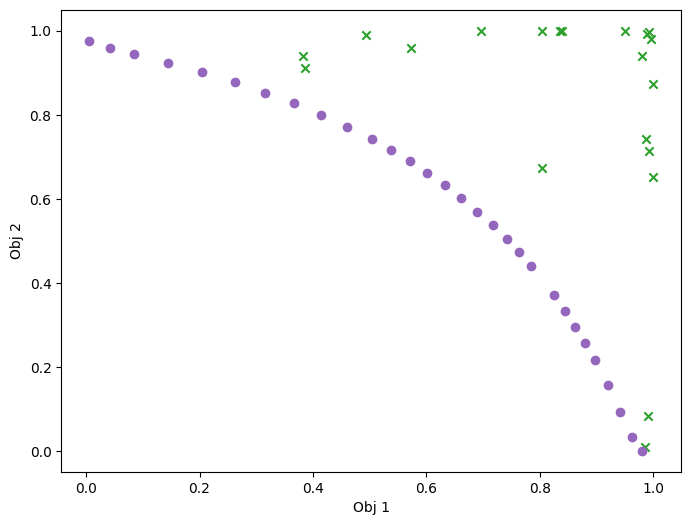
We can have a look at the results, as in the previous case. For this relatively simple problem, the greedy heuristic works quite well, and the performance is similar to the non-batch run.
[18]:
dataset = batch_result.try_get_final_dataset()
batch_data_query_points = dataset.query_points
batch_data_observations = dataset.observations
_, ax = plot_function_2d(
vlmop2.objective,
mins,
maxs,
contour=True,
figsize=(12, 6),
title=["Obj 1", "Obj 2"],
xlabel="$X_1$",
ylabel="$X_2$",
colorbar=True,
)
plot_bo_points(
batch_data_query_points, ax=ax[0, 0], num_init=num_initial_points
)
plot_bo_points(
batch_data_query_points, ax=ax[0, 1], num_init=num_initial_points
)
plt.show()
plot_mobo_points_in_obj_space(
batch_data_observations, num_init=num_initial_points
)
plt.show()
fig, ax = plot_mobo_history(
batch_data_observations, log_hv, num_init=num_initial_points
)
ax.set_xlabel("Iterations")
ax.set_ylabel("log HV difference")
plt.show()
Multi-objective optimization with constraints#
EHVI can be adapted to the case of constraints, as we show below. We start by defining a problem with the same objectives as above, but with an inequality constraint, and we define the corresponding Observer.
[19]:
class Sim:
threshold = 0.75
@staticmethod
def objective(input_data):
return vlmop2.objective(input_data)
@staticmethod
def constraint(input_data):
x, y = input_data[:, -2], input_data[:, -1]
z = tf.cos(x) * tf.cos(y) - tf.sin(x) * tf.sin(y)
return z[:, None]
OBJECTIVE = "OBJECTIVE"
CONSTRAINT = "CONSTRAINT"
def observer_cst(query_points):
return {
OBJECTIVE: Dataset(query_points, Sim.objective(query_points)),
CONSTRAINT: Dataset(query_points, Sim.constraint(query_points)),
}
num_initial_points = 10
initial_query_points = search_space.sample(num_initial_points)
initial_data_with_cst = observer_cst(initial_query_points)
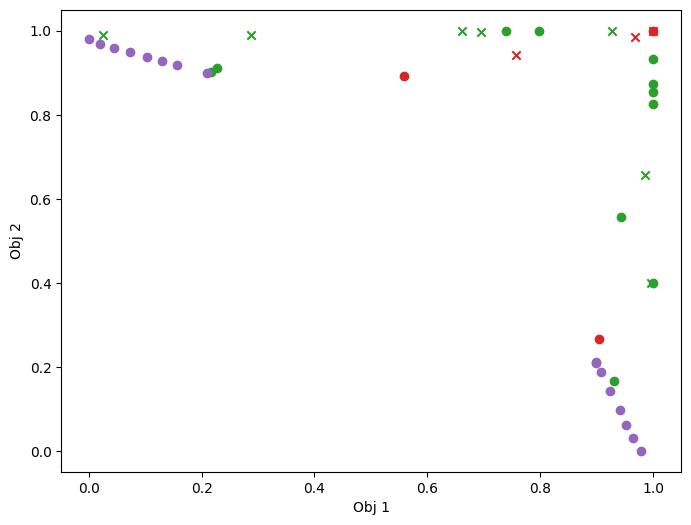
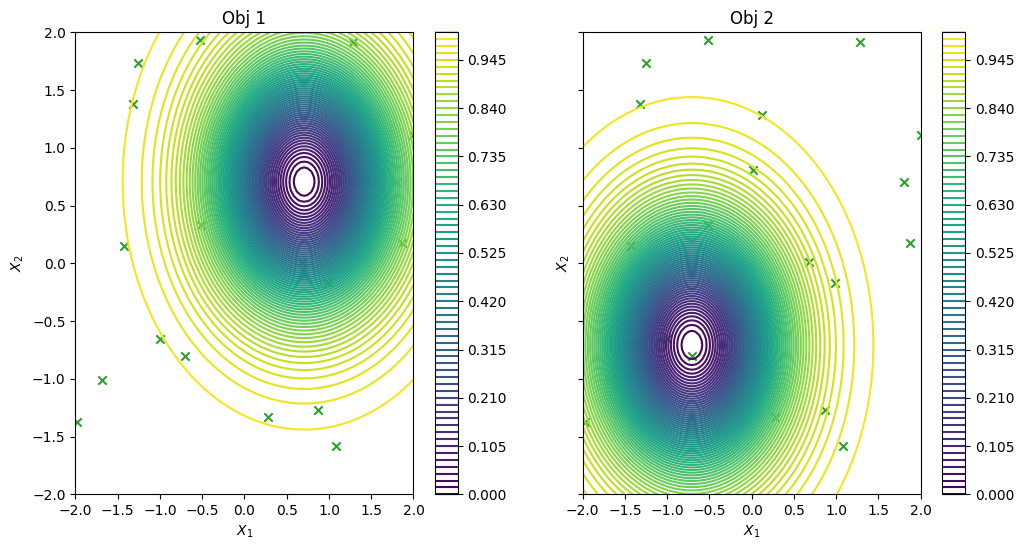
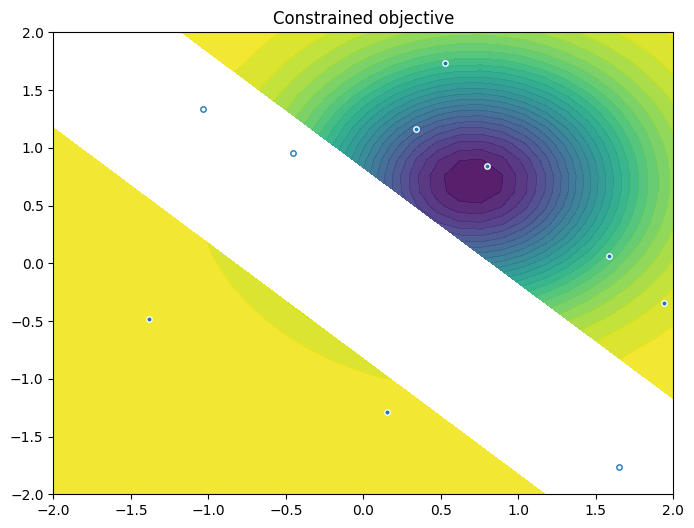
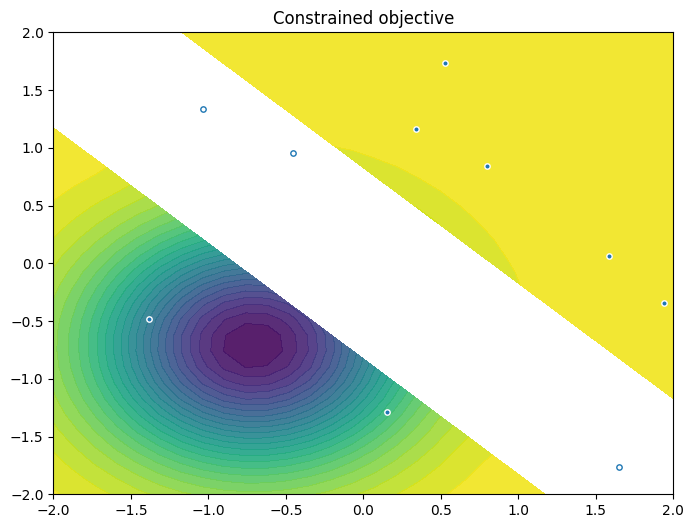
As previously, we visualise the data across the design space: each figure contains the contour lines of each objective function and in the objective space. The plot_mobo_points_in_obj_space will automatically search for non-dominated points and colours them in purple, and the points in red violate the constraint.
[20]:
from trieste.experimental.plotting import plot_2obj_cst_query_points
plot_2obj_cst_query_points(
search_space,
Sim,
initial_data_with_cst[OBJECTIVE].astuple(),
initial_data_with_cst[CONSTRAINT].astuple(),
)
plt.show()
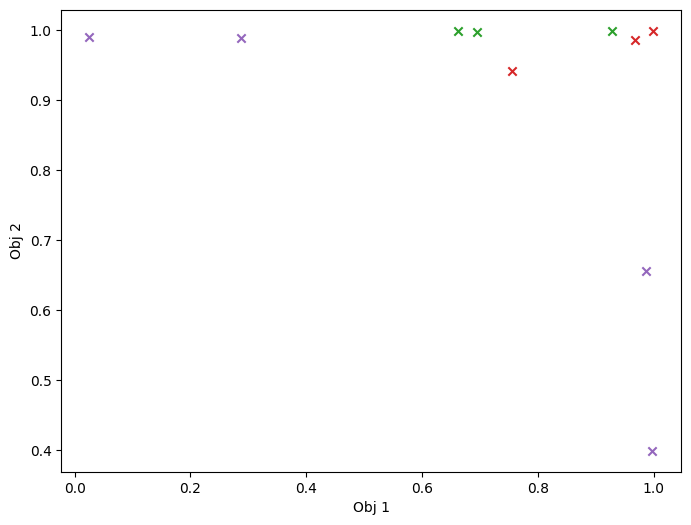
mask_fail = (
initial_data_with_cst[CONSTRAINT].observations.numpy() > Sim.threshold
)
plot_mobo_points_in_obj_space(
initial_data_with_cst[OBJECTIVE].observations, mask_fail=mask_fail[:, 0]
)
plt.show()
We use the same model wrapper to build and stack the two GP models of the objective:
[21]:
objective_model = build_stacked_independent_objectives_model(
initial_data_with_cst[OBJECTIVE], num_objective, search_space
)
We also create a single model of the constraint. Note that we set the likelihood variance to a small number because we are dealing with a noise-free problem.
[22]:
gpflow_model = build_gpr(
initial_data_with_cst[CONSTRAINT], search_space, likelihood_variance=1e-7
)
constraint_model = GaussianProcessRegression(gpflow_model)
We store both sets of models in a dictionary:
[23]:
models = {OBJECTIVE: objective_model, CONSTRAINT: constraint_model}
Acquisition function for multiple objectives and constraints#
We utilize the ExpectedConstrainedHypervolumeImprovement acquisition function, which is the product of EHVI (based on the feasible Pareto set) with the probability of feasibility:
[24]:
from trieste.acquisition.function import (
ExpectedConstrainedHypervolumeImprovement,
)
pof = trieste.acquisition.ProbabilityOfFeasibility(threshold=Sim.threshold)
echvi = ExpectedConstrainedHypervolumeImprovement(
OBJECTIVE, pof.using(CONSTRAINT)
)
rule = EfficientGlobalOptimization(builder=echvi)
We can now run the optimization loop
[25]:
num_steps = 30
bo = trieste.bayesian_optimizer.BayesianOptimizer(observer_cst, search_space)
result = bo.optimize(
num_steps, initial_data_with_cst, models, acquisition_rule=rule
)
WARNING:tensorflow:5 out of the last 5 calls to <function probability_below_threshold.__call__ at 0x7f5ed2c92b90> triggered tf.function retracing. Tracing is expensive and the excessive number of tracings could be due to (1) creating @tf.function repeatedly in a loop, (2) passing tensors with different shapes, (3) passing Python objects instead of tensors. For (1), please define your @tf.function outside of the loop. For (2), @tf.function has reduce_retracing=True option that can avoid unnecessary retracing. For (3), please refer to https://www.tensorflow.org/guide/function#controlling_retracing and https://www.tensorflow.org/api_docs/python/tf/function for more details.
WARNING:tensorflow:6 out of the last 6 calls to <function probability_below_threshold.__call__ at 0x7f5ed2c92b90> triggered tf.function retracing. Tracing is expensive and the excessive number of tracings could be due to (1) creating @tf.function repeatedly in a loop, (2) passing tensors with different shapes, (3) passing Python objects instead of tensors. For (1), please define your @tf.function outside of the loop. For (2), @tf.function has reduce_retracing=True option that can avoid unnecessary retracing. For (3), please refer to https://www.tensorflow.org/guide/function#controlling_retracing and https://www.tensorflow.org/api_docs/python/tf/function for more details.
Optimization completed without errors
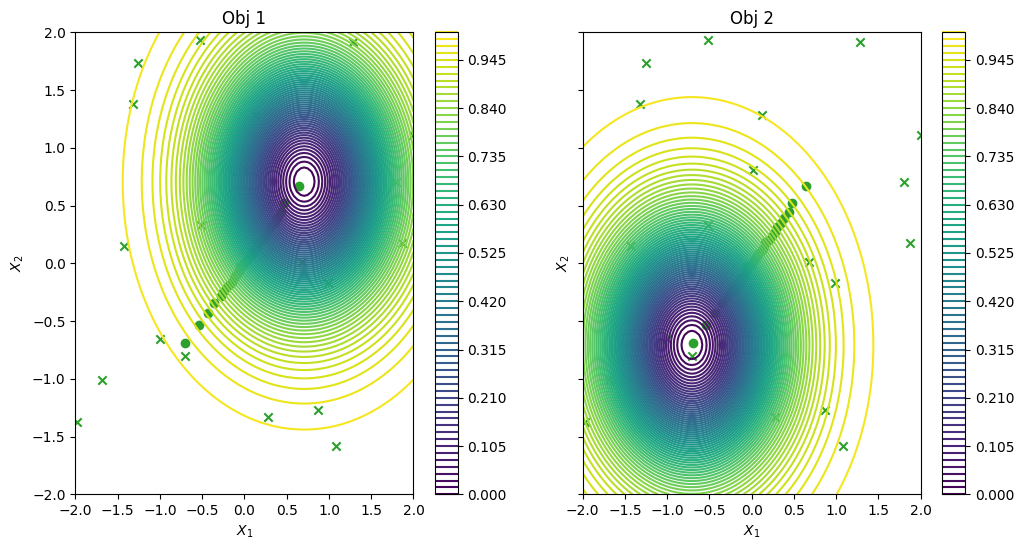
As previously, we visualize the queried data across the design space. We represent the initial points as crosses and the points obtained by our optimization loop as dots.
[26]:
objective_dataset = result.final_result.unwrap().datasets[OBJECTIVE]
constraint_dataset = result.final_result.unwrap().datasets[CONSTRAINT]
data_query_points = objective_dataset.query_points
data_observations = objective_dataset.observations
plot_2obj_cst_query_points(
search_space,
Sim,
objective_dataset.astuple(),
constraint_dataset.astuple(),
)
plt.show()
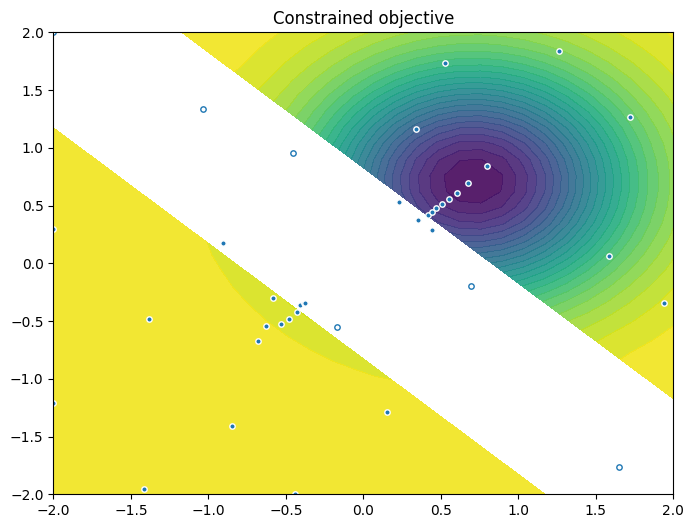
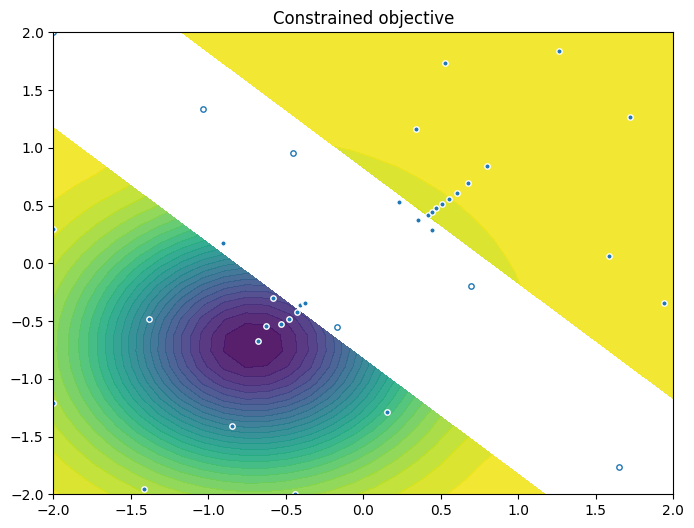
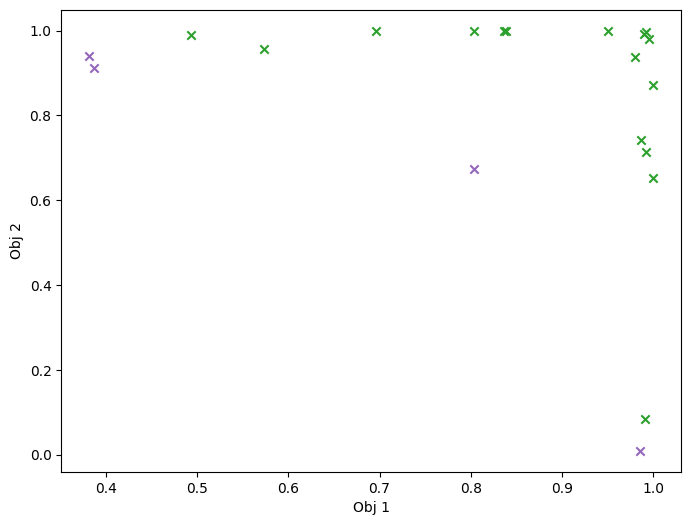
Finally, we visualize them in the objective space. Purple dots denote the non-dominated points, and red ones the points that violate the constraint.
[27]:
mask_fail = constraint_dataset.observations.numpy() > Sim.threshold
plot_mobo_points_in_obj_space(
data_observations, num_init=num_initial_points, mask_fail=mask_fail[:, 0]
)
plt.show()