Noise-free optimization with Expected Improvement#
[1]:
import numpy as np
import tensorflow as tf
np.random.seed(1793)
tf.random.set_seed(1793)
Describe the problem#
In this example, we look to find the minimum value of the two-dimensional Branin function over the hypercube \([0, 1]^2\). The Branin function is a popular toy function used in Bayesian optimization literature. Trieste provides a selection of toy functions in trieste.objectives package, where besides the functions we also provide their minimizers, minima and search space definitions.
Below we use a version of the Branin function scaled to the hypercube search space. For the Branin we use the predefined search space, but otherwise one would define the search space directly using a Box object (illustrated below as well). We also plot contours of the Branin over the search space.
[2]:
from trieste.objectives import ScaledBranin
from trieste.experimental.plotting import plot_function_plotly
from trieste.space import Box
scaled_branin = ScaledBranin.objective
search_space = ScaledBranin.search_space # predefined search space
search_space = Box([0, 0], [1, 1]) # define the search space directly
fig = plot_function_plotly(
scaled_branin,
search_space.lower,
search_space.upper,
)
fig.show()
Sample the observer over the search space#
Sometimes we don’t have direct access to the objective function. We only have an observer that indirectly observes it. In Trieste, an observer can output a number of datasets. In our case, we only have one dataset, the objective. We can convert a function with branin’s signature to a single-output observer using mk_observer.
The optimization procedure will benefit from having some starting data from the objective function to base its search on. We sample a five point space-filling design from the search space and evaluate it with the observer. For continuous search spaces, Trieste supports random, Sobol and Halton initial designs.
[3]:
import trieste
observer = trieste.objectives.utils.mk_observer(scaled_branin)
num_initial_points = 5
initial_query_points = search_space.sample_sobol(num_initial_points)
initial_data = observer(initial_query_points)
Model the objective function#
The Bayesian optimization procedure estimates the next best points to query by using a probabilistic model of the objective. We’ll use Gaussian Process (GP) regression for this, as provided by GPflow. The model will need to be trained on each step as more points are evaluated, by default it uses GPflow’s Scipy optimizer.
The GPflow models cannot be used directly in our Bayesian optimization routines, only through a valid model wrapper. Trieste has wrappers that support several popular models. For instance, GPR and SGPR models from GPflow have to be used with GaussianProcessRegression wrapper. These wrappers standardise outputs from all models, deal with preparation of the data and implement additional methods needed for Bayesian optimization. Below we construct a GPR model from GPflow and pass it
to the GaussianProcessRegression wrapper. Wrappers as a rule have an optimizer argument and potentially some additional model arguments (for example, num_kernel_samples as explained below). All arguments except for the model are set to sensible defaults, users will need to look up the wrapper to check how to customize these settings.
Note below that we put priors on the parameters of our GP model’s kernel in order to stabilize model fitting. We found the priors below to be highly effective for objective functions defined over the unit hypercube and with an ouput standardized to have zero mean and unit variance. For objective functions with different scaling, other priors will likely be more appropriate. Our fitted model uses the maximum a posteriori estimate of these kernel parameters, as found by optimizing the kernel
parameters starting from the best of num_kernel_samples random samples from the kernel parameter priors. For illustration we set the num_kernel_samples to 100 (default value is 10). If we do not specify kernel priors, then Trieste returns the maximum likelihood estimate of the kernel parameters.
[4]:
import gpflow
import tensorflow_probability as tfp
from trieste.models.gpflow import GaussianProcessRegression
def build_model(data):
variance = tf.math.reduce_variance(data.observations)
kernel = gpflow.kernels.Matern52(variance=variance, lengthscales=[0.2, 0.2])
prior_scale = tf.cast(1.0, dtype=tf.float64)
kernel.variance.prior = tfp.distributions.LogNormal(
tf.cast(-2.0, dtype=tf.float64), prior_scale
)
kernel.lengthscales.prior = tfp.distributions.LogNormal(
tf.math.log(kernel.lengthscales), prior_scale
)
gpr = gpflow.models.GPR(data.astuple(), kernel, noise_variance=1e-5)
gpflow.set_trainable(gpr.likelihood, False)
return GaussianProcessRegression(gpr, num_kernel_samples=100)
model = build_model(initial_data)
Constructing a GPflow model can be somewhat involved and take a dozen lines of non-trivial code. Hence, Trieste has build functions for the supported GPflow models. For example, for the GPR model we would use a build_gpr model building function, that sets sensible initial parameters and priors, almost exactly the same as seen above. We have found these settings to be effective in most cases.
[5]:
from trieste.models.gpflow import build_gpr
gpflow_model = build_gpr(initial_data, search_space, likelihood_variance=1e-7)
model = GaussianProcessRegression(gpflow_model, num_kernel_samples=100)
Run the optimization loop#
We can now run the Bayesian optimization loop by defining a BayesianOptimizer and calling its optimize method.
The optimizer uses an acquisition rule to choose where in the search space to try on each optimization step. We’ll use the default acquisition rule, which is Efficient Global Optimization with Expected Improvement.
We’ll run the optimizer for fifteen steps.
The optimization loop catches errors so as not to lose progress, which means the optimization loop might not complete and the data from the last step may not exist. Here we’ll handle this crudely by asking for the data regardless, using .try_get_final_datasets(), which will re-raise the error if one did occur. For a review of how to handle errors systematically, there is a dedicated tutorial.
[6]:
bo = trieste.bayesian_optimizer.BayesianOptimizer(observer, search_space)
num_steps = 15
result = bo.optimize(num_steps, initial_data, model)
dataset = result.try_get_final_dataset()
Optimization completed without errors
In this tutorial we will manually explore the results once the optimization loop completes. For how to monitor the loop in realtime, including some of the plots shown below, see visualizing and tracking optimizations using Tensorboard.
Explore the results#
We can now get the best point found by the optimizer. Note this isn’t necessarily the point that was last evaluated.
[7]:
query_point, observation, arg_min_idx = result.try_get_optimal_point()
print(f"query point: {query_point}")
print(f"observation: {observation}")
query point: [0.54222747 0.152613 ]
observation: [-1.04738653]
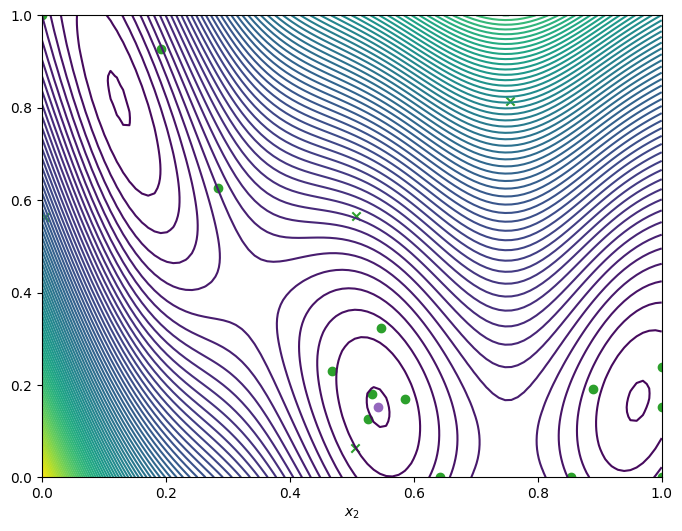
We can visualise how the optimizer performed by plotting all the acquired observations, along with the true function values and optima, either in a two-dimensional contour plot …
[8]:
from trieste.experimental.plotting import plot_bo_points, plot_function_2d
query_points = dataset.query_points.numpy()
observations = dataset.observations.numpy()
_, ax = plot_function_2d(
scaled_branin,
search_space.lower,
search_space.upper,
contour=True,
)
plot_bo_points(query_points, ax[0, 0], num_initial_points, arg_min_idx)
ax[0, 0].set_xlabel(r"$x_1$")
ax[0, 0].set_xlabel(r"$x_2$")
[8]:
Text(0.5, 0, '$x_2$')
/opt/hostedtoolcache/Python/3.10.12/x64/lib/python3.10/site-packages/matplotlib/_mathtext.py:1880: UserWarning:
warn_name_set_on_empty_Forward: setting results name 'sym' on Forward expression that has no contained expression
/opt/hostedtoolcache/Python/3.10.12/x64/lib/python3.10/site-packages/matplotlib/_mathtext.py:1885: UserWarning:
warn_ungrouped_named_tokens_in_collection: setting results name 'name' on ZeroOrMore expression collides with 'name' on contained expression
… or as a three-dimensional plot
[9]:
from trieste.experimental.plotting import add_bo_points_plotly
fig = plot_function_plotly(
scaled_branin,
search_space.lower,
search_space.upper,
)
fig = add_bo_points_plotly(
x=query_points[:, 0],
y=query_points[:, 1],
z=observations[:, 0],
num_init=num_initial_points,
idx_best=arg_min_idx,
fig=fig,
)
fig.show()
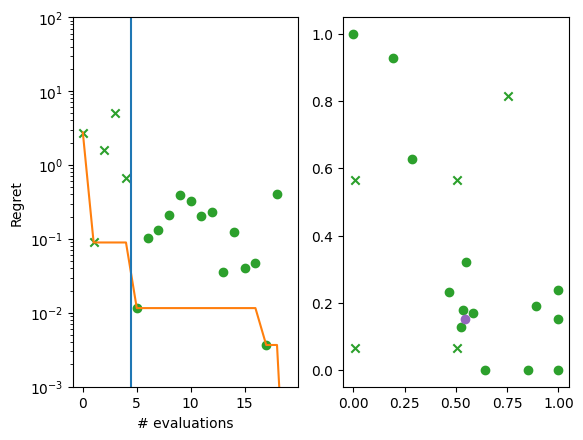
We can also visualise the how each successive point compares the current best.
We produce two plots. The left hand plot shows the observations (crosses and dots), the current best (orange line), and the start of the optimization loop (blue line). The right hand plot is the same as the previous two-dimensional contour plot, but without the resulting observations. The best point is shown in each (purple dot).
[10]:
import matplotlib.pyplot as plt
from trieste.experimental.plotting import plot_regret
suboptimality = observations - ScaledBranin.minimum.numpy()
_, ax = plt.subplots(1, 2)
plot_regret(
suboptimality, ax[0], num_init=num_initial_points, idx_best=arg_min_idx
)
plot_bo_points(
query_points, ax[1], num_init=num_initial_points, idx_best=arg_min_idx
)
ax[0].set_yscale("log")
ax[0].set_ylabel("Regret")
ax[0].set_ylim(0.001, 100)
ax[0].set_xlabel("# evaluations")
[10]:
Text(0.5, 0, '# evaluations')
We can visualise the model over the objective function by plotting the mean and 95% confidence intervals of its predictive distribution. Like with the data before, we can get the model with .try_get_final_model().
[11]:
from trieste.experimental.plotting import plot_model_predictions_plotly
fig = plot_model_predictions_plotly(
result.try_get_final_model(),
search_space.lower,
search_space.upper,
)
fig = add_bo_points_plotly(
x=query_points[:, 0],
y=query_points[:, 1],
z=observations[:, 0],
num_init=num_initial_points,
idx_best=arg_min_idx,
fig=fig,
figrow=1,
figcol=1,
)
fig.show()
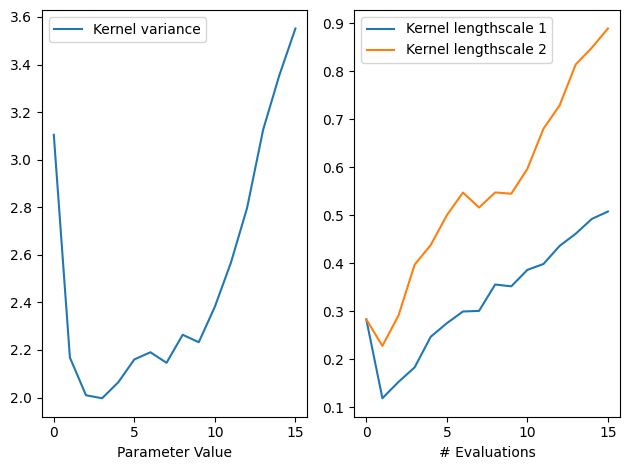
We can also inspect the model hyperparameters, and use the history to see how the length scales evolved over iterations. By default, the model history is kept in memory though it’s possibe to store it to disk instead using optimize’s track_path argument (see this tutorial). Note also the history is saved at the start of each step, and as such never includes the final result, so we’ll add that ourselves.
[12]:
gpflow.utilities.print_summary(
result.try_get_final_model().model # type: ignore
)
variance_list = [
step.model.model.kernel.variance.numpy() # type: ignore
for step in result.history + [result.final_result.unwrap()]
]
ls_list = [
step.model.model.kernel.lengthscales.numpy() # type: ignore
for step in result.history + [result.final_result.unwrap()]
]
variance = np.array(variance_list)
ls = np.array(ls_list)
fig, ax = plt.subplots(1, 2)
ax[0].plot(variance, label="Kernel variance")
ax[0].legend(loc="upper left")
ax[0].set_xlabel("# Evaluations")
ax[0].set_xlabel("Parameter Value")
ax[1].plot(ls[:, 0], label="Kernel lengthscale 1")
ax[1].plot(ls[:, 1], label="Kernel lengthscale 2")
ax[1].legend(loc="upper left")
ax[1].set_xlabel("# Evaluations")
fig.tight_layout()
╒═════════════════════════╤══════════════════╤══════════════════╤═══════════╤═════════════╤═══════════╤═════════╤═══════════════════════╕
│ name │ class │ transform │ prior │ trainable │ shape │ dtype │ value │
╞═════════════════════════╪══════════════════╪══════════════════╪═══════════╪═════════════╪═══════════╪═════════╪═══════════════════════╡
│ GPR.mean_function.c │ Parameter │ Identity │ │ True │ () │ float64 │ 1.41751 │
├─────────────────────────┼──────────────────┼──────────────────┼───────────┼─────────────┼───────────┼─────────┼───────────────────────┤
│ GPR.kernel.variance │ Parameter │ Softplus │ LogNormal │ True │ () │ float64 │ 3.55163 │
├─────────────────────────┼──────────────────┼──────────────────┼───────────┼─────────────┼───────────┼─────────┼───────────────────────┤
│ GPR.kernel.lengthscales │ Parameter │ Softplus │ LogNormal │ True │ (2,) │ float64 │ [0.50766 0.88905] │
├─────────────────────────┼──────────────────┼──────────────────┼───────────┼─────────────┼───────────┼─────────┼───────────────────────┤
│ GPR.likelihood.variance │ Parameter │ Softplus + Shift │ │ False │ () │ float64 │ 0.0 │
├─────────────────────────┼──────────────────┼──────────────────┼───────────┼─────────────┼───────────┼─────────┼───────────────────────┤
│ GPR.data[0] │ ResourceVariable │ │ │ False │ (None, 2) │ float64 │ [[0.75563, 0.81419... │
├─────────────────────────┼──────────────────┼──────────────────┼───────────┼─────────────┼───────────┼─────────┼───────────────────────┤
│ GPR.data[1] │ ResourceVariable │ │ │ False │ (None, 1) │ float64 │ [[1.69841... │
╘═════════════════════════╧══════════════════╧══════════════════╧═══════════╧═════════════╧═══════════╧═════════╧═══════════════════════╛
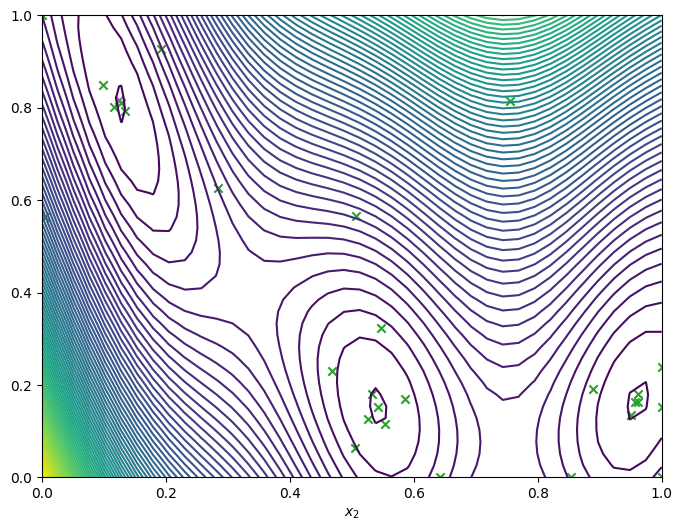
Run the optimizer for more steps#
If we need more iterations for better convergence, we can run the optimizer again using the data produced from the last run, as well as the model. We’ll visualise the final data.
[13]:
num_steps = 10
result = bo.optimize(
num_steps, result.try_get_final_dataset(), result.try_get_final_model()
)
dataset = result.try_get_final_dataset()
_, _, arg_min_idx = result.try_get_optimal_point()
_, ax = plot_function_2d(
scaled_branin,
search_space.lower,
search_space.upper,
grid_density=40,
contour=True,
)
plot_bo_points(
dataset.query_points.numpy(),
ax=ax[0, 0],
num_init=len(dataset.query_points),
idx_best=arg_min_idx,
)
ax[0, 0].set_xlabel(r"$x_1$")
ax[0, 0].set_xlabel(r"$x_2$")
Optimization completed without errors
[13]:
Text(0.5, 0, '$x_2$')
Save the results#
Trieste provides two ways to save and restore optimization results. The first uses pickling to save the results (including the datasets and models), allowing them to be easily reloaded. Note however that is not portable and not secure. You should only try to load optimization results that you generated yourself on the same system (or a system with the same version libraries).
[14]:
# save the results to a given path
result.save("results_path")
# load the results
saved_result = trieste.bayesian_optimizer.OptimizationResult.from_path( # type: ignore
"results_path"
)
saved_result.try_get_final_model().model # type: ignore
[14]:
| name | class | transform | prior | trainable | shape | dtype | value |
|---|---|---|---|---|---|---|---|
| GPR.mean_function.c | Parameter | Identity | True | () | float64 | 2.53978 | |
| GPR.kernel.variance | Parameter | Softplus | LogNormal | True | () | float64 | 5.16351 |
| GPR.kernel.lengthscales | Parameter | Softplus | LogNormal | True | (2,) | float64 | [0.54678 1.13682] |
| GPR.likelihood.variance | Parameter | Softplus + Shift | False | () | float64 | 0.0 | |
| GPR.data[0] | ResourceVariable | False | (None, 2) | float64 | [[0.75563, 0.81419... | ||
| GPR.data[1] | ResourceVariable | False | (None, 1) | float64 | [[1.69841... |
The second approach is to save the model using the tensorflow SavedModel format. This requires explicitly exporting the methods to be saved and results in a portable model than can be safely loaded and evaluated, but which can no longer be used in subsequent BO steps.
[15]:
# save the model to a given path, exporting just the predict method
module = result.try_get_final_model().get_module_with_variables()
module.predict = tf.function(
model.predict,
input_signature=[tf.TensorSpec(shape=[None, 2], dtype=tf.float64)],
)
tf.saved_model.save(module, "model_path")
# load the model
saved_model = tf.saved_model.load("model_path")
saved_model.predict(initial_query_points)
# compare prediction results
query_points = search_space.sample_sobol(1)
print("Original model prediction: ", model.predict(query_points))
print("Saved model prediction: ", saved_model.predict(query_points))
INFO:tensorflow:Assets written to: model_path/assets
Original model prediction: (<tf.Tensor: shape=(1, 1), dtype=float64, numpy=array([[-0.94119204]])>, <tf.Tensor: shape=(1, 1), dtype=float64, numpy=array([[0.00030433]])>)
Saved model prediction: (<tf.Tensor: shape=(1, 1), dtype=float64, numpy=array([[-0.94119204]])>, <tf.Tensor: shape=(1, 1), dtype=float64, numpy=array([[0.00030433]])>)