Mixed search spaces#
This notebook demonstrates optimization of mixed search spaces in Trieste.
The example function is defined over 2D input space that is a combination of a discrete and a continuous search space. The problem is a modification of the Branin function where one of the input dimensions is discretized.
[1]:
import numpy as np
import tensorflow as tf
np.random.seed(1793)
tf.random.set_seed(1793)
The problem#
The Branin function is a common optimization benchmark that has three global minima. It is normally defined over a 2D continuous search space.
We first show the Branin function over its original continuous search space.
[2]:
from trieste.experimental.plotting import plot_function_plotly
from trieste.objectives import ScaledBranin
scaled_branin = ScaledBranin.objective
fig = plot_function_plotly(
scaled_branin,
ScaledBranin.search_space.lower,
ScaledBranin.search_space.upper,
)
fig.show()
2026-06-17 10:55:48,489 INFO util.py:154 -- Missing packages: ['ipywidgets']. Run `pip install -U ipywidgets`, then restart the notebook server for rich notebook output.
Data type cannot be displayed: application/vnd.plotly.v1+json
In order to convert the Branin function from a continuous to a mixed search space problem, we modify it by discretizing its first input dimension.
The discrete dimension is defined by a set of 10 points that are equally spaced, ensuring that the three minimizers are included in this set. The continuous dimension is defined by the interval [0, 1].
We observe that the first and third minimizers are equidistant from the middle minimizer, so we choose the discretization points to be equally spaced around the middle minimizer.
The TaggedProductSearchSpace class is a convenient way to define a search space that is a combination of multiple search spaces, each with an optional tag. We create our mixed search space by instantiating this class with a list containing the discrete and continuous spaces, without any explicit tags (hence using default tags). This can be easily extended to more than two search spaces by adding more elements to the list.
Note: the dtype of all the component search spaces must be the same.
[3]:
from trieste.space import Box, DiscreteSearchSpace, TaggedProductSearchSpace
minimizers0 = ScaledBranin.minimizers[:, 0]
step = (minimizers0[1] - minimizers0[0]) / 4
points = np.concatenate(
[
# Equally spaced points to the left of the middle minimizer. Skip the last point as it is
# the same as the first point in the next array.
np.flip(np.arange(minimizers0[1], 0.0, -step))[:-1],
# Equally spaced points to the right of the middle minimizer.
np.arange(minimizers0[1], 1.0, step),
]
)
discrete_space = DiscreteSearchSpace(points[:, None])
continuous_space = Box([0.0], [1.0])
mixed_search_space = TaggedProductSearchSpace(
[discrete_space, continuous_space]
)
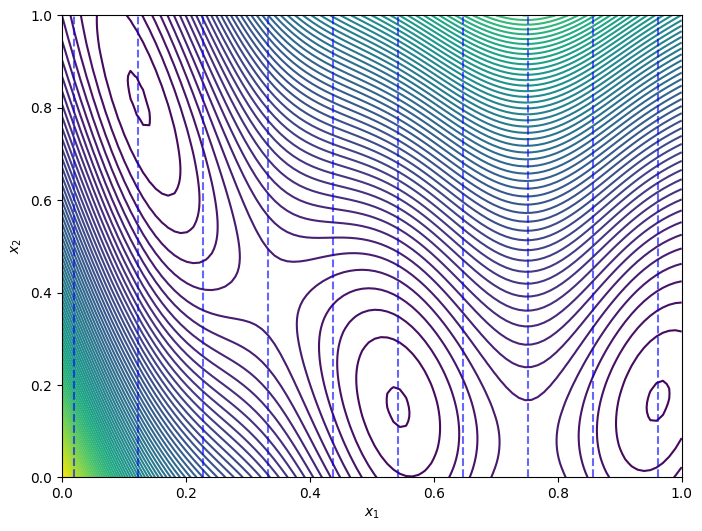
Next we demonstrate the Branin function over the mixed search space, by plotting the original function contours and highlighting the discretization points. The discrete dimension is along the x-axis and the continuous dimension is on the y-axis, with the vertical dashed lines indicating the discretization points.
[4]:
from trieste.experimental.plotting import plot_function_2d
# Plot over the predefined search space.
fig, ax = plot_function_2d(
scaled_branin,
ScaledBranin.search_space.lower,
ScaledBranin.search_space.upper,
contour=True,
)
ax[0, 0].set_xlabel(r"$x_1$")
ax[0, 0].set_ylabel(r"$x_2$")
# Draw vertical lines at the discrete points.
for point in points:
ax[0, 0].vlines(
point,
mixed_search_space.lower[1],
mixed_search_space.upper[1],
colors="b",
linestyles="dashed",
alpha=0.6,
)
Sample the observer over the search space#
We begin our optimization by first collecting five function evaluations from random locations in the mixed search space. Samples from the discrete dimension are drawn uniformly at random with replacement, and samples from the continuous dimension are drawn from a uniform distribution. Observe that the sample method deals with the mixed search space automatically.
[5]:
from trieste.objectives import mk_observer
observer = mk_observer(scaled_branin)
num_initial_points = 5
initial_query_points = mixed_search_space.sample(num_initial_points)
initial_data = observer(initial_query_points)
Model the objective function#
We now build a Gaussian process model of the objective function using the initial data, similar to the introduction notebook.
Since all of the data in this example is quantitative, the model does not differentiate between the discrete and continuous dimensions of the search space. The Gaussian process regression model treats all dimensions as continuous variables, allowing for a seamless integration of both types of dimensions in the optimization process.
[6]:
from trieste.models.gpflow import GaussianProcessRegression, build_gpr
gpflow_model = build_gpr(
initial_data, mixed_search_space, likelihood_variance=1e-7
)
model = GaussianProcessRegression(gpflow_model)
Run the optimization loop#
The Bayesian optimization loop is run for 15 steps over the mixed search space. For each step, the optimizer fixes the discrete dimension to the best points found from a random initial search, and then optimizes the continuous dimension using a gradient-based method. This dispatch of discrete and continuous optimization is handled by the optimizer automatically.
[7]:
from trieste.bayesian_optimizer import BayesianOptimizer
bo = BayesianOptimizer(observer, mixed_search_space)
num_steps = 15
result = bo.optimize(num_steps, initial_data, model)
dataset = result.try_get_final_dataset()
Optimization completed without errors
Explore the results#
We can now get the best point found by the optimizer. Note that this isn’t necessarily the last evaluated point.
[8]:
query_point, observation, arg_min_idx = result.try_get_optimal_point()
print(f"query point: {query_point}")
print(f"observation: {observation}")
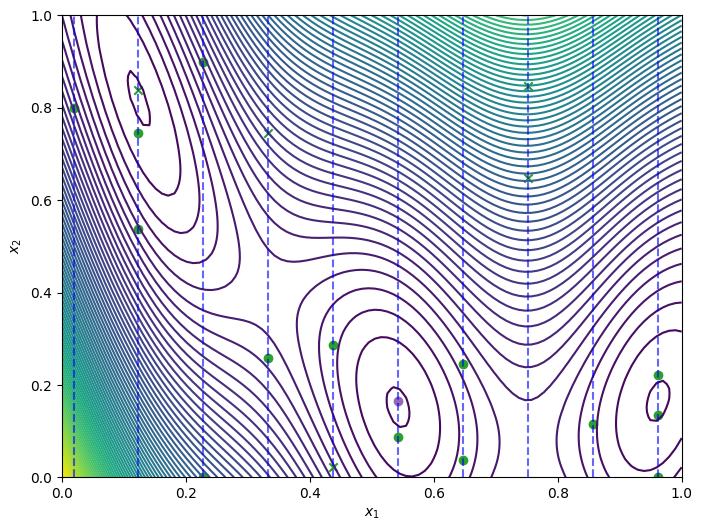
query point: [0.54277284 0.16439408]
observation: [-1.04669231]
The plot below highlights how the optimizer explored the mixed search space over the course of the optimization loop. The green ‘x’ markers indicate the initial points, the green circles mark the points evaluated during the optimization loop, and the purple circle indicates the optimal point found by the optimizer.
[9]:
from trieste.experimental.plotting import plot_bo_points
query_points = dataset.query_points.numpy()
observations = dataset.observations.numpy()
_, ax = plot_function_2d(
scaled_branin,
ScaledBranin.search_space.lower,
ScaledBranin.search_space.upper,
contour=True,
)
plot_bo_points(query_points, ax[0, 0], num_initial_points, arg_min_idx)
ax[0, 0].set_xlabel(r"$x_1$")
ax[0, 0].set_ylabel(r"$x_2$")
for point in points:
ax[0, 0].vlines(
point,
mixed_search_space.lower[1],
mixed_search_space.upper[1],
colors="b",
linestyles="dashed",
alpha=0.6,
)
Trust region with mixed search spaces#
In this section, we demonstrate the use of trust region acquisition rules with mixed search spaces. We use the same mixed search space and observer as before, and the same initial data. See trust region Bayesian optimization notebook for an introduction to trust region acquisition rules.
First we build a Gaussian process model of the objective function using the initial data.
[10]:
gpflow_model = build_gpr(
initial_data, mixed_search_space, likelihood_variance=1e-7
)
model = GaussianProcessRegression(gpflow_model)
We create a trust region meta acquisition rule that uses efficient global optimization (EGO) as the base rule. The trust region rule is initialized with a set of trust regions; 5 in this example. Each trust regions is defined as a product of a discrete and a continuous trust sub-region, analogous to a TaggedProductSearchSpace. The base rule is then called to optimize the acquisition function within each region.
This setup is similar to the one used in the “Batch trust region rule” section of the trust region Bayesian optimization notebook. That notebook creates trust regions of type SingleObjectiveTrustRegionBox. Here, we create trust regions that are a product of a discrete and a continuous trust sub-region with UpdatableTrustRegionProduct. The continuous part SingleObjectiveTrustRegionBox is the same as in the trust region notebook, but now as a sub-region. The
discrete sub-region is implemented by SingleObjectiveTrustRegionDiscrete, which follows a very similar algorithm to the continuous one, but with a region defined by a set of neighboring points. Both the continuous and discrete sub-regions are updated at each step of the optimization.
Note that SingleObjectiveTrustRegionDiscrete is designed for discrete numerical variables only, which we have in this example. It is not suitable for qualitative (categorical, ordinal and binary) variables.
[11]:
from trieste.acquisition import ParallelContinuousThompsonSampling
from trieste.acquisition.rule import (
BatchTrustRegionProduct,
EfficientGlobalOptimization,
SingleObjectiveTrustRegionBox,
SingleObjectiveTrustRegionDiscrete,
UpdatableTrustRegionProduct,
)
num_query_points = 5
init_regions = [
UpdatableTrustRegionProduct(
[
SingleObjectiveTrustRegionDiscrete(discrete_space),
SingleObjectiveTrustRegionBox(continuous_space),
]
)
for _ in range(num_query_points)
]
base_rule = EfficientGlobalOptimization( # type: ignore[var-annotated]
builder=ParallelContinuousThompsonSampling(),
num_query_points=num_query_points,
)
tr_acq_rule = BatchTrustRegionProduct(init_regions, base_rule)
We run the optimization loop for 15 steps using the trust region acquisition rule.
[12]:
bo = BayesianOptimizer(observer, mixed_search_space)
num_steps = 15
tr_result = bo.optimize(
num_steps, initial_data, model, tr_acq_rule, track_state=True
)
dataset = tr_result.try_get_final_dataset()
Optimization completed without errors
The best point found by the optimizer is obtained as before.
[13]:
query_point, observation, arg_min_idx = tr_result.try_get_optimal_point()
print(f"query point: {query_point}")
print(f"observation: {observation}")
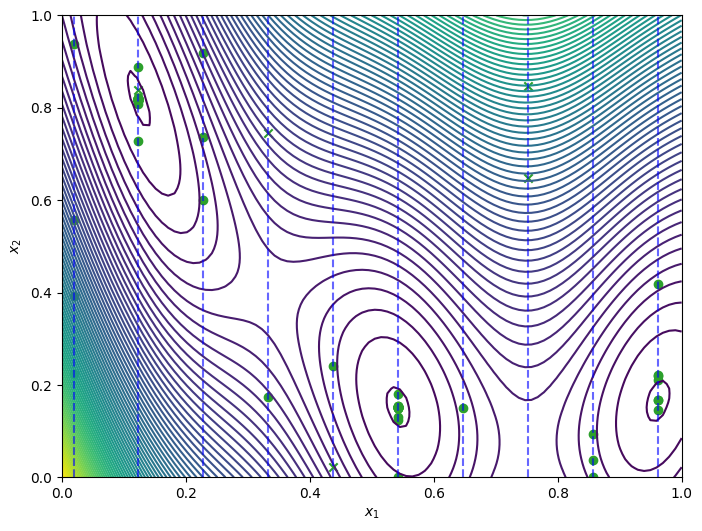
query point: [0.54277284 0.15166761]
observation: [-1.04739389]
Plot of the optimization loop over the mixed search space, similar to the previous plot.
[14]:
query_points = dataset.query_points.numpy()
observations = dataset.observations.numpy()
_, ax = plot_function_2d(
scaled_branin,
ScaledBranin.search_space.lower,
ScaledBranin.search_space.upper,
contour=True,
)
plot_bo_points(query_points, ax[0, 0], num_initial_points, arg_min_idx)
ax[0, 0].set_xlabel(r"$x_1$")
ax[0, 0].set_ylabel(r"$x_2$")
for point in points:
ax[0, 0].vlines(
point,
mixed_search_space.lower[1],
mixed_search_space.upper[1],
colors="b",
linestyles="dashed",
alpha=0.6,
)
Finally, we visualize the optimization progress by plotting the 5 (product) trust regions at each step. The trust regions are shown as translucent boxes, with each box in a different color. The new query point for earch region is plotted in matching color.
Note that since the discrete dimension is on the x-axis, the trust regions sometimes appear as vertical lines with zero width. This occurs when a region contains only a single point along the discrete dimension.
[15]:
import base64
from typing import Optional
import IPython
import matplotlib.pyplot as plt
from trieste.bayesian_optimizer import OptimizationResult
from trieste.experimental.plotting import (
convert_figure_to_frame,
convert_frames_to_gif,
plot_trust_region_history_2d,
)
def plot_history(
result: OptimizationResult,
num_query_points: Optional[int] = None,
) -> None:
frames = []
for step, hist in enumerate(
result.history + [result.final_result.unwrap()]
):
fig, _ = plot_trust_region_history_2d(
scaled_branin,
ScaledBranin.search_space.lower,
ScaledBranin.search_space.upper,
hist,
num_query_points=num_query_points,
num_init=num_initial_points,
alpha=0.6,
)
if fig is not None:
fig.suptitle(f"step number {step}")
frames.append(convert_figure_to_frame(fig))
plt.close(fig)
gif_file = convert_frames_to_gif(frames)
gif = IPython.display.HTML(
'<img src="data:image/gif;base64,{0}"/>'.format(
base64.b64encode(gif_file.getvalue()).decode()
)
)
IPython.display.display(gif)
plot_history(tr_result)
